NIST Likely Exploited Vulnerability Model - Helpful, But Not a Game Changer!

Jun 17, 2025

Abhilash Hota
This article examines NIST’s new Likely Exploited Vulnerability (LEV) and LEV2 models, which estimate the probability that a vulnerability has already been exploited, complementing existing models and data sources, such as EPSS and CISA KEV. While promising, LEV and LEV2 are not a panacea and require further empirical assessment.
Blind Spots - We All Have Them
IT security professionals are often faced with a seemingly impossible task: knowing your infrastructure down to the last detail, tracking everything, patching everything, and consequently burning out your operations team, or trying to prioritize what needs to be patched first. This might earn some respite for your operations team but leaves you open to risk from whatever gets deprioritized. Models like the Exploit Prediction Scoring System (EPSS) try to score the likelihood of future exploitation, but what about vulnerabilities already being exploited in the wild? EPSS doesn’t take into account what threat actors are currently exploiting. Meanwhile, exploited vulnerability databases, such as CISA’s Known Exploited Vulnerabilities (KEV) catalog, provide a list of CVEs that CISA knows to have been exploited. However, the coverage of this or other third-party KEVs is an open question and varies depending on the degree of visibility that the managing organization is currently capable of.
These blind spots translate to real-world business impact. Organizations can waste precious resources on theoretical threats while missing vulnerabilities with confirmed exploitation. Compliance frameworks often require evidence-based risk assessment, yet quantitative measures of detection completeness and coverage can be lacking.
Introducing NIST LEV & LEV2: Probability Models for Past Exploitation
NIST has recently proposed two models, LEV (Likely Exploited Vulnerability) and LEV2, that could address this gap by estimating the probability that a CVE has already been exploited - without the need for any evidence.
LEV operates on 30-day windows. It’s a lightweight model for overnight batch processing that could complement existing vulnerability management workflows.
LEV2 provides daily granularity for a higher-resolution analysis to track exploitation probability with greater temporal precision.
Both models fundamentally try to answer the question: “Given the observations about similar vulnerabilities, what’s the likelihood that any given vulnerability has been exploited?”. Rather than predicting future exploitation like EPSS, LEV/LEV2 work backward from observable patterns to estimate past exploitation likelihood. The idea is to complement EPSS with respect to already exploited vulnerabilities.
The models ingest CVE metadata, EPSS score histories, and CISA KEV flags to build their probability estimates.
What the Data Reveals
The following analysis is based on over 150 000 vulnerabilities with available historical EPSS data.
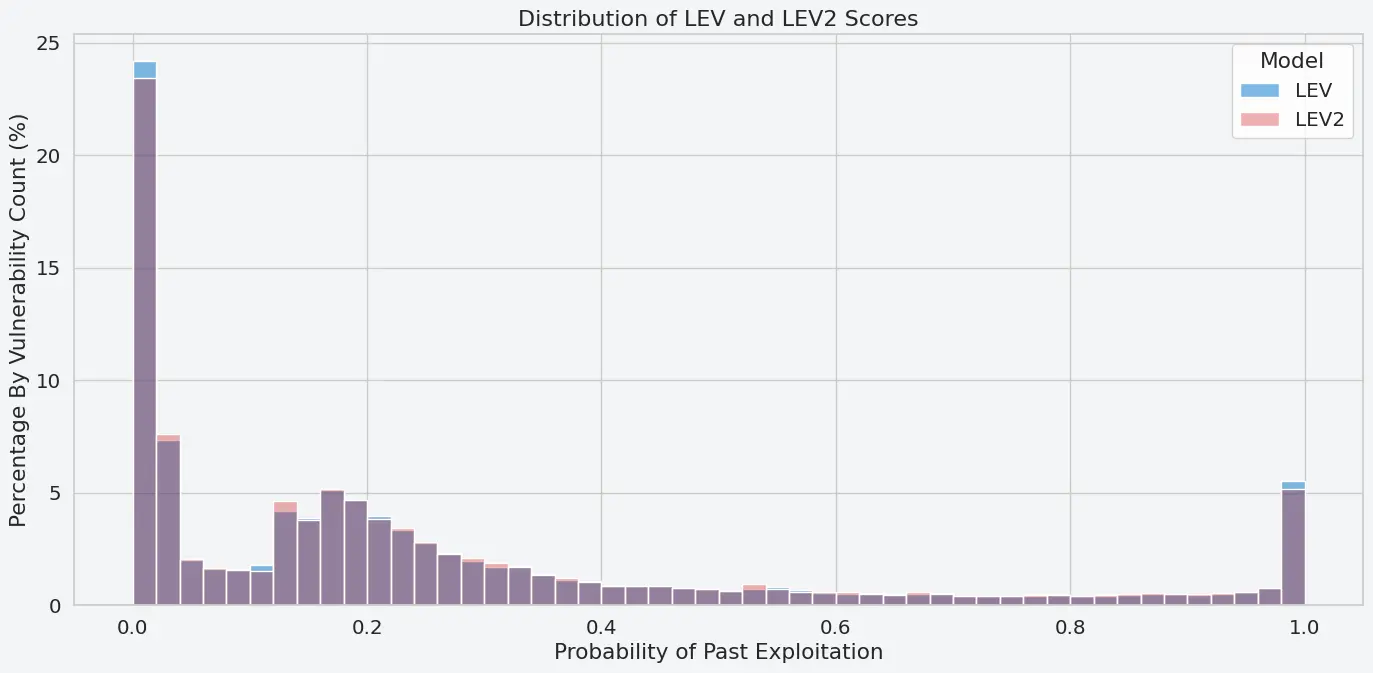
Distribution Differences: As a first step, the LEV and LEV2 scores have been calculated, i.e., the probability of these vulnerabilities being likely exploited. The following illustration shows the probability distribution of the analyzed vulnerabilities. LEV and LEV2 show fairly similar results, with LEV having a slightly higher distribution towards the extremes as compared to LEV2.
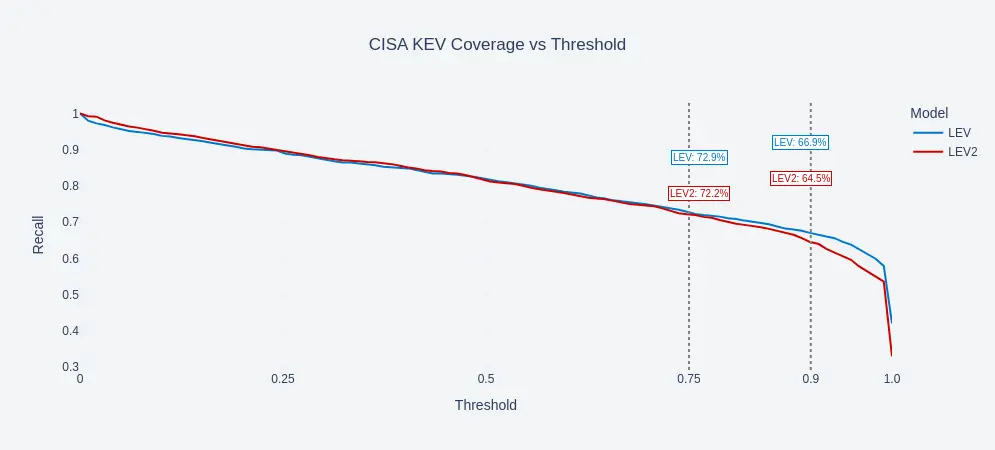
Validation with CISA KEV: As a second step, we validate the results taking CISA KEV as the ground truth, since vulnerabilities landing on CISA KEV have evidence of past exploitation. To this end, we assess the CISA KEV coverage at different threshold values. The results show as the threshold value increases, the models become more selective. At a threshold of 0.75, LEV achieves 72.9% coverage, and LEV2 slightly trails at 72.2%. When the threshold is raised to 0.90, the coverage drops to 66.9% for LEV and 64.5% for LEV2. This demonstrates the trade-off between the strictness of classification and completeness of KEV identification.
Our Take on NIST LEV & LEV2
LEV/LEV2, while interesting, have some significant limitations:
Empirical Validation: The models’ assumptions need further validation against private exploit logs.
Sparse Data: CVEs with limited EPSS history or delayed scoring can yield unreliable estimates, particularly for new vulnerabilities.
KEV Scope Limitations: CISA KEV reflects a U.S.-centric threat analysis and collection; other geographic regions or private vulnerability lists may yield different completeness ratios.
Threat Intelligence Complement: LEV identifies probable past exploitation but doesn’t account for environment or industry-specific trends.
Our Recommendations for Security Teams
For Security Practitioners:
- Monitor KEV completeness ratios nightly to maintain coverage aligned with your risk appetite
- Investigate “high-LEV but missing from KEV” CVEs for threat intelligence enrichment
- Use completeness trends to demonstrate threat intelligence maturity to stakeholders
For Security Researchers:
- Leverage completeness curves to optimize classification threshold selection
- Identify vendor or product-specific blind spots through completeness analysis
- Correlate LEV scores with internal telemetry or third-party threat exploit activity feeds to validate model assumptions
Conclusion
LEV and LEV2 aim to add a further metric to vulnerability prioritization, providing a quantitative measure to estimate potential past exploitation. They seem interesting as a means for scoring KEV completeness. That said, these models are inherently probabilistic, and as such, their effectiveness will depend heavily on the availability of data and the underlying EPSS model. Validation and data sparsity remain open challenges that will ultimately impact whether the models see significant adoption in vulnerability prioritization workflows.